Alors que l’analyse de données est devenue indispensable pour outiller la croissance de toute entreprise, le concept de « Data Hub » attire l’attention de plus en plus de professionnels de la donnée, du fait de sa capacité à se positionner au cœur d’une stratégie globale de traitement de l’information. Mais comment positionner ce concept face aux architectures existantes, qui parfois viennent juste d’être déployées ? Un Data Hub va-t-il rendre obsolète mon Data Lake, ou va-t-il remplacer nos traditionnels Data Warehouse ? Et si je choisis de déployer un Data Hub, quels types de données vais-je y traiter et avec quels objectifs ? En résumé, le déploiement d’un Data Hub a-t-il du sens dans votre contexte et quels en seront les bénéfices ?
Mais avant de répondre à toutes ces questions, commençons par comprendre quelle est l’origine du concept de Data Hub.
Aborder le partage des données de manière isolée a conduit à la création d’environnements complexes
L’évolution des demandes de partage et d’intégration de données s’est faite graduellement. Les organisations y ont naturellement répondu en utilisant leurs architectures traditionnelles. Puis, les flux point à point se sont multipliés pour faire circuler les données à travers les silos, avec des traitements adaptés à chaque consommation, et une gouvernance réduite à sa plus simple expression. Cette stratégie a débouché sur des efforts informatiques ou technologiques disparates et cloisonnés, qui ont limité la capacité des producteurs et des consommateurs de données à interagir facilement. Dans le même temps, les échanges point à point ont généré de nouvelles difficultés. Dans les échanges inter-applicatifs, comment réconcilier les données d’un produit ou d’un client ? Et qui a raison en cas de conflit ? Ces interrogations ont fait émerger des besoins de gouvernance des données, principalement focussées sur les données de référence ou Master Data, avec parfois des arbitrages difficiles, et une intégration complexe dans les applications. Tous ces points ont mis en exergue des besoins de qualité, d’unicité, et de transparence que les architectures traditionnelles sont incapables de prendre en charge. Et c’est normal, elles n’ont pas été conçues pour ça.
De nouvelles solutions pour répondre à la multiplication des besoins de partage d’informations
Avec l’essor de la digitalisation des entreprises, de nouveaux besoins d’exploration des données ont vu le jour et toutes ces difficultés ont été démultipliées. Les services IT ont pu répondre par la mise en œuvre de bus d’échanges de données, en considérant toujours l’application métier avec ses données silotées comme la source unique de l’information. Pourtant, les besoins transactionnels des applications ne correspondent pas à tous les usages.
Parallèlement à ces difficultés, les obligations réglementaires sont devenues de plus en plus fortes. Que ce soit sur les données personnelles avec le RGPD européen, ou la révision de la LPD suisse qui en sera fortement influencée, ou encore sur les réglementations bancaires, toutes ont ajouté une complexité supplémentaire que la dispersion des informations ne contribue pas à réduire.
Pour de nombreuses entreprises, il est alors devenu indispensable de remplacer les anciennes interfaces point à point, et les flux de données manquant de médiation cohérente. Leur objectif est de réduire la complexité et la fragilité des mécanismes de partage des données, tout en progressant vers l’introduction d’une gouvernance cohérente, de définitions communes et d’une plus grande transparence dans la circulation des données au sein de l’organisation.
Alors, comment faire face, et surtout ne pas bouleverser des systèmes d’informations parfois fragiles ?
Choisir la bonne architecture en fonction du besoin
Certains responsables de données ont choisi de mettre en place une nouvelle architecture de type Data Lake.
Mais avant de développer, il est nécessaire de bien comprendre la finalité des trois types d’architecture Data existants, et le rôle qu’elles peuvent jouer dans une infrastructure moderne de gestion des données.
Toutes ces architectures s’alimentent selon les mêmes procédés. Leurs différences résident principalement dans la sélection des données candidates, dans le traitement des données reçues, et dans leurs usages.
Entrepôt de données ou Data Warehouse
Un entrepôt de données est une base de données relationnelle pensée et structurée de façon précise pour le reporting et les analyses de données. Il répond à des besoins analytiques prédéfinis et reproductibles, facilitant la prise de décision et les activités de type Business Intelligence. Ainsi, l’entrepôt de données est le mieux adapté aux exigences d’une sémantique cohérente, et répond à des cas d’utilisation très ciblés. D’ailleurs, les données stockées dans l’entrepôt sont agrégées selon les cas d’utilisation pour permettre aux utilisateurs d’y accéder rapidement et facilement.
La mise en œuvre d’entrepôts de données apporte des réponses performantes à des besoins analytiques complexes et identifiés, portant sur de grands volumes de données. La qualité des données y est généralement bonne. En revanche, ce type d’architecture est peu adapté à l’analyse exploratrice, et sa conception engendre généralement des déphasages entre la demande métier originale et la mise à disposition des indicateurs. Cette approche est à privilégier pour des indicateurs de performances clairement identifiés, à destination d’une large population. Le Data Warehouse est le fruit d’un processus d’industrialisation et de consolidation, avec une structuration forte des données.
Data Lake
Un Data Lake est un collecteur de données permettant de stocker et traiter une très large quantité et variété de données, structurées ou brutes (c’est-à-dire conservées dans leur format natif) pour une durée indéterminée. Cette méthode de stockage permet de faciliter la cohabitation entre les différents schémas et formes structurelles de données.
L’ensemble des données de l’entreprise est stocké au sein d’un seul Data Lake. Les données brutes côtoient les données transformées. Elles sont utilisées pour établir des rapports, pour en visualiser les contenus, pour l’analyse de données ou pour le Machine Learning, mais nécessitent des traitements manuels (préparation) de la part des utilisateurs.
Par la concentration des données de l’entreprise, le Data Lake devient la source unique de systèmes exploratoires, d’activités d’analyse, et de science des données, avec potentiellement un large éventail de sujets et de consommateurs.
Data Hub
Le terme de Data Hub est apparu il y a environ 4 ans. Il s’agit d’une convergence naturelle des concepts d’entrepôt de données et de Data Lake, répondant à des besoins mixtes.
Comme pour les Hubs d’aéroport ou de traitement logistique, le Data Hub traduit la concentration des informations en un lieu central et commun, servant de point de transit et de distribution jusqu’à de multiples destinations. Il se situe donc au centre des traitements et du stockage, et la variété des destinations n’est pas figée. Elle dépend principalement de la richesse des informations qu’il porte.
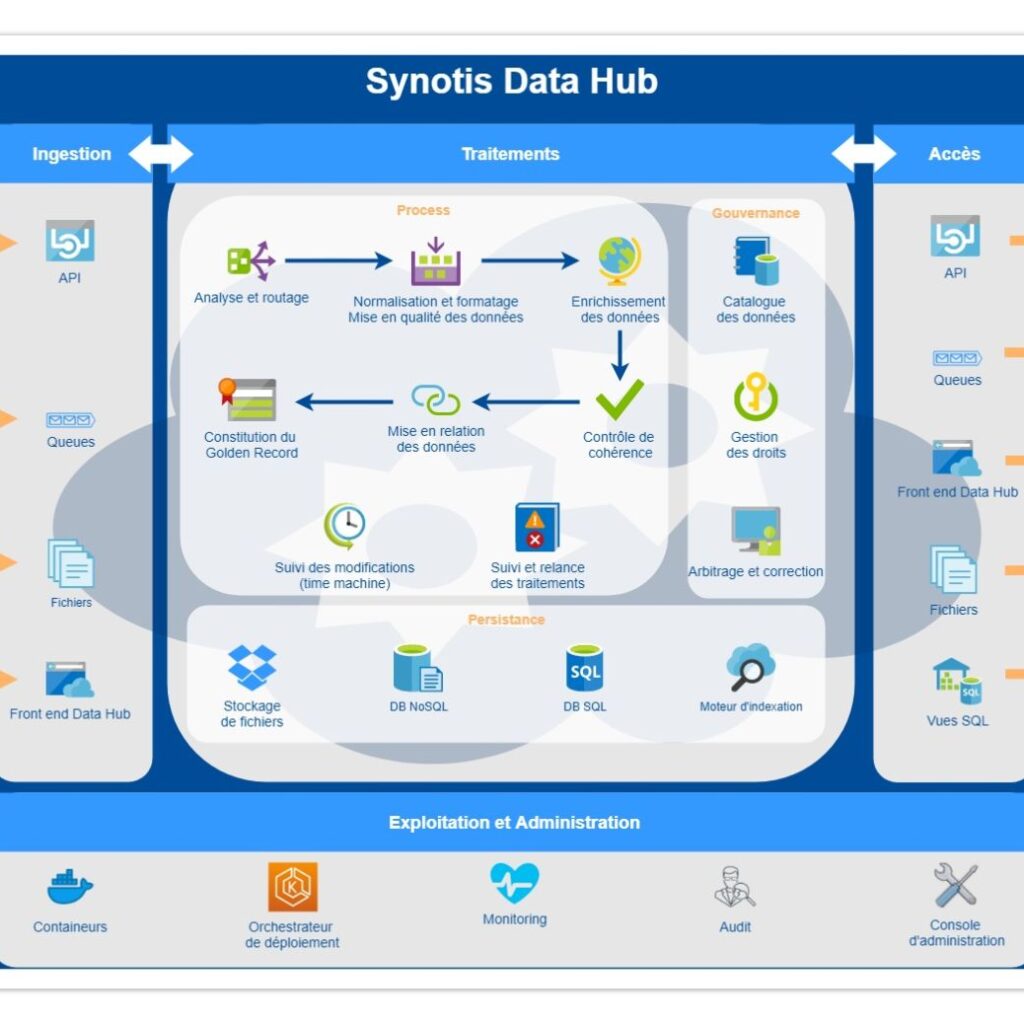
Le Data Hub assure donc les accès aux données stratégiques de l’entreprise, mais il peut aussi en assurer la persistance sur une plateforme de stockage, en regroupant un ensemble de données en provenance de systèmes d’informations multiples, ou au contraire être une passerelle entre les silos transactionnels et les points de consommation. Son objectif est de fournir une source de données unifiée et centralisée, qui permet un partage gérable et régi des données. Le Data Hub est donc un modèle architectural permettant la circulation et la gouvernance transparente des données. Les connexions entre producteurs et consommateurs s’établissent via le Data Hub, avec des contrôles de gouvernance et des modèles standards appliqués pour permettre un partage des données optimal.
Avec un Data Hub l’entreprise retrouve la capacité à maîtriser l’un de ses actifs les plus stratégiques : son capital données.
Pourquoi Synotis privilégie l’approche Data Hub ?
Son positionnement au centre des usages rend le Data Hub particulièrement efficace sur l’ensemble des sujets adressés par Synotis pour ses clients : qualité de données, gestion des données de référence, gouvernance et conformité des données, mais aussi de contrôle de la persistance et des cycles de vie.
La concentration des données permet l’homogénéisation des règles de traitement et de distribution, qui sont alors définies par la gouvernance, en collaboration avec tous les métiers.
En réalité, il n’existe pas une, mais des architectures Data Hub. Chacune pouvant répondre à des besoins différents :
- Partager des données transactionnelles entre les processus opérationnels ;
- Assurer la cohérence des données de base essentielles entre les fonctions de l’entreprise ;
- Fournir des données analytiques à un ensemble diversifié d’équipes d’analyse ;
- Permettre aux populations de Data Scientist d’explorer et d’affiner les données.
Avec des choix technologiques adaptés, il est également possible de prendre en charge une combinaison de ses besoins.
Reposant sur le concept de modèles communs à toute l’entreprise, les Data Hub sont principalement axés sur de la sémantique cohérente, mais peuvent soutenir une série de cas d’utilisation (à la fois opérationnels et en soutien des besoins analytiques), et des stratégies de traitement (via des choix de persistance des données techniques, styles d’intégration et méthodes d’accès) :
Plate-forme de données de base ou données principales
Axé sur le partage cohérent des données principales (client, produit …) à travers les systèmes et les processus opérationnels de l’entreprise. Ce type de plate-forme est courant dans les organisations qui ont mis en œuvre des initiatives de gestion des données principales.
Plate-forme de données d’application
Se concentre sur les systèmes opérationnels complexes avec des fonctionnalités diverses. Le Data Hub sert de point central de contrôle et de partage des données clés dans le contexte d’une application ou d’une suite spécifique.
Plate-forme de données d’intégration
Un Data Hub axé sur l’intégration peut permettre le partage de tous les types de données (de base, transactionnelles, analytiques). Il utilise diverses techniques d’intégration des données, et des applications, pour traiter et fournir un large éventail de données répondant aux exigences de partage. Ce type de Data Hub peut également s’étendre au-delà des frontières de l’entreprise, permettant le partage de données avec des partenaires extérieurs (clients, fournisseurs, etc.).
Plate-forme de données de référence
Semblable aux Data Hub de données de base, et d’application, mais avec une focalisation étroite sur les « données de référence » (codes, tableaux, hiérarchies, etc.) couramment utilisées. Ces plateformes permettent un accès cohérent et une synchronisation de ces données, généralement entre les centres opérationnels et les systèmes d’analyses.
Plate-forme de données analytiques
En tant que point de collecte et de partage des données et des résultats analytiques, ce style de Data Hub peut prendre en charge l’approvisionnement en données de Data Warehouses et d’autres solutions analytiques. Elle permet principalement de mutualiser les efforts de traitement de qualité des données, et allège donc les systèmes producteurs.
Les caractéristiques de l’architecture Data Hub
Il convient de considérer cette architecture comme un ensemble de bonnes pratiques plutôt que comme une architecture figée et rigide. Ses implémentations peuvent prendre des formes variées, adaptées aux différents cas d’usage, et sa mise en œuvre relève plus d’un puzzle dans lequel peuvent s’imbriquer de nombreuses technologies. Mais elles sont toujours assemblées pour fournir un résultat cohérent et optimal.
Un Data Hub a pour avantage de pouvoir être intégré par étape, en privilégiant la prise en compte des axes les plus stratégiques de nos clients. Dans certains cas, la mise en persistance du capital données est prioritaire, dans d’autres, c’est la distribution d’information avec un traitement homogène de l’information. Le traitement des données de référence prend naturellement sa place au centre du système d’information.
Le Data Hub selon Synotis
Pour résumer en quelques mots, l’objectif d’un Data Hub est de rendre simple, abordable, facile, flexible, rapide et efficace, à la fois l’intégration, mais aussi l’utilisation de toutes les données, tout en assurant la sécurité et la gouvernance des données candidates au partage.
Nos experts architectes sont à votre disposition pour détailler les avantages d’une architecture Data Hub, en fonction du contexte propre à votre entreprise. Nous vous proposons d’étudier vos contraintes afin de vous apporter des réponses pragmatiques et de vous soutenir dans vos efforts de rationalisation de votre architecture Data.
contact@synotis.ch