Du 7 au 10 janvier 2019 se tenait à Colorado Spring (USA/CO) le kick off annuel de Talend , connu sous le nom d‘ « Engage », a rassemblé plus de 700 personnes, commerciaux, pre-sales, customer success manager, customer success architect, marketing, mais également les partenaires stratégiques de l’éditeur et certains de ses clients ;
En tant que partenaire gold de Talend, Synotis était présent comme chaque année à cet événement. Une présence indispensable qui nous permet de prendre connaissance de la stratégie de Talend, tant au niveau marché que produit, mais également de prendre contact et d’échanger avec les équipes en charge des produits , etc. .
Après un Talend Engage 2018 marqué par la thématique « Star Wars », c’est le film « Top Gun » qui a été choisi cette année comme fil rouge de l’événement avec une baseline orienté cloud : « CLOUD COMBAT TRAINING – Earn your wings ».
Dans cet article je vais donc essayer de couvrir les principales annonces et enseignement de ce Talend Engage 2019 .
En premier lieu, ce qui m’a frappé c’est le changement de dimension de Talend. Exit le statut de « visionnaire » du Magic Quadrant de Gartner pour les solutions d’intégration de données, Talend est aujourd’hui considéré comme un « Leader » et un acteur mature de la data. Ressenti confirmé auprès des commerciaux () : aujourd’hui Talend est vu comme un acteur pérenne et comptant dans le monde de la data notamment auprès des grands groupes du CAC 40.
Ce sentiment est renforcé par le fait que l’écosystème de Talend ne cesse de s’élargir d’année en année. Après l’arrivée de Talend Data Preparation et de Talend Data Stewardship (TDS), les rachats successifs en 2017 et en 2018 de Restlet et de Stitch enrichissent encore un peu plus la gamme de produits proposés par Talend. Ce n’est pas moins de 13 Product Managers qui se sont présentés devant nous pour jouer au jeu des questions/réponses sur la roadmap 2019. Là encore, changement de dimension : 3 ans auparavant seulement 5 Product Managers étaient présents.

Les PMs on stage – un moment d’interaction mené par Cyaran Dimes, VP Products de Talend.
Cloud, Cloud, Cloud…
Le discours est, sans surprise, encore cette année orienté sur le Cloud. 2 ans en arrière, Talend annonçait le lancement de sa plateforme Talend Cloud. Même s’il était indispensable de suivre ce chemin, j’avoue avoir été sceptique à l’époque. Le Cloud, c’est un métier à part entière. Gérer les disponibilités des plateformes, livrer des releases impactant tous les tenants Cloud, etc… nécessite un vrai savoir-faire qui est totalement différent du savoir-faire historique de l’éditeur. Même si cette transition n’a pas été un long fleuve tranquille. Le fait est qu’à l’heure d’aujourd’hui le pari semble en passe d’être réussi : Talend Cloud est en pleine expansion et séduit de plus en plus de clients. Les retours d’expériences sur scène des clients UNIPER et TI Media (entre autres) ont mis en avant les avantages du cloud (flexibilité, scalabilité, innovation continue…). Des retours d’expérience un peu trop parfait à mon goût. J’aurais souhaité avoir plus d’informations sur les écueils rencontrés lors du passage d’un mode on-premise traditionnel vers le cloud.
Une cohérence de l’écosystème CLOUD
Laurent Bride a présenté sa vision de Talend Cloud : « More integration, integrity, intelligence ». Et sur cette vision 4 étapes majeures en lien avec les outils en place
- Collecter : grâce à Stitch Data Loader,
- Gouverner :
- Data Catalog (ex Talend Metadata Manager),
- Data Quality,
- Data Stewardship.
- Transformer :
- Data Streams
- Data Integration via Studio,
- Data Preparation.
L’arrivé du Frictionless
Au détour d’une slide, apparaît le terme de « Frictionless », soit un nouveau processus de consommation du logiciel : facile à utiliser et facile à acheter, sans la contrainte d’un processus de vente ou d’un contrat à long terme. Intéressant. Le mode de licence traditionnel de Talend est le mode « souscription ». Le client souscrit à une licence pour une durée de 1 à 5 ans. Licence renouvelable à échéance.
Le Frictionless est la vision développée par certains acteurs du Cloud tel AWS ou Azure, et également hérité de l’acquisition de Stitch
Pas question néanmoins aujourd’hui de placer totalement la plateforme Cloud sous ce nouveau mode de consommation. Certains services seront mis à disposition au fur et à mesure. De premières annonces sont attendus pour le 2ème trimestre
Une petite nouveauté pour l’équipe Sales de Talend (et ses partenaires) qui vont devoir adapter leur discours auprès des clients.
Et le On-Premise dans tout ça….
Et bien ce kick off était clairement placé sous le signe du cloud…
Côté on-premise, Data Catalog était à l’honneur. Certaines annonces côté CLOUD permettent aussi d’entrevoir l’arrivée de nouvelles features dans le Studio
La place de l’ETL dans cet écosystème
Avec le rachat de Stitch, le développement de Data Streams et du traditionnel Studio, ce n’est pas moins de 3 produits différents qui permettent de faire de l’ETL.
La question évidente est donc de savoir quand et comment positionner Stitch, Pipeline Designer ou le Studio.
Deux contextes principaux :
- Si vous n’êtes pas adepte du Cloud, alors la réponse est basique. Seul le Studio On Premise vous permettra de créer vos flux de données.
- Si vous êtes dans une stratégie Cloud, alors la réponse peut être trouvée en fonction du niveau de complexité du flux développé :
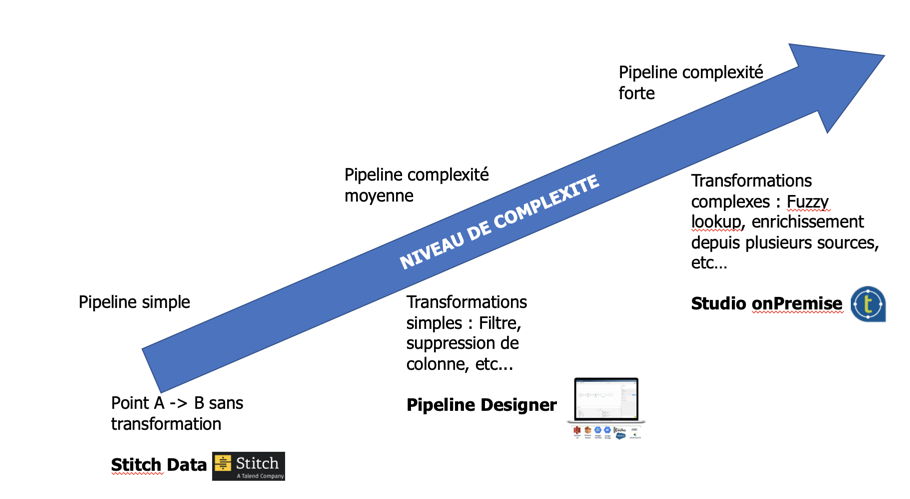
Il s’agit évidemment d’une vulgarisation en fonction d’un critère basique.
D’autres critères peuvent entrer en jeu : connecteur disponible ou non, format de la données, etc… N’hésitez pas à nous contacter pour discuter de vos problématiques. Nous sommes en mesure de vous accompagner sur cette prise de décision.
Des partenariats techniques majeurs
Enfin, Talend met de plus en plus en place des partenariats technologiques forts.
- Microsoft pour la partie Machine Learning sur Azure. Plusieurs annonces renforçant le partenariat Talend et Microsoft émailleront tout au long de l’année 2019
- Databricks a pour vocation de réunir Data Engineer et Data Scientist tout au long du cycle de vie du Machine Learning, de la préparation des données à l’expérimentation et au déploiement d’applications ML. Plateforme basée sur Spark. La relation est au beau fixe entre Databricks et Talend avec une forte collaboration entre le Product Manager Big Data de Talend et le Product Manager de Databricks.
- Snowflake: Depuis maintenant 2 ans, Talend promeut Snowflake (DW dans le cloud) et met à disposition tant sur le on premise que sur le cloud les connecteurs pour charger ou interroger Snowflake.
En synthèse, un super un événement avec notre partenaire Talend.
Nous y avons appris de nombreuses choses concernant la stratégie et l’évolution des produits de l’éditeur.
Si vous voulez en savoir plus, contactez Xavier, le rédacteur



 Après de nombreux échanges afin de nous mettre d’accord sur le lieu et sur les activités, un consensus fut trouvé et notre séminaire d’entreprise annuel nous a mené à Zermatt. Station de ski suisse emblématique, cette destination est tout autant appréciée l’été. C’est donc avec impatience que l’ensemble de l’équipe Synotis attendait le jour J pour se rend dans ce havre de paix montagnard.
Après de nombreux échanges afin de nous mettre d’accord sur le lieu et sur les activités, un consensus fut trouvé et notre séminaire d’entreprise annuel nous a mené à Zermatt. Station de ski suisse emblématique, cette destination est tout autant appréciée l’été. C’est donc avec impatience que l’ensemble de l’équipe Synotis attendait le jour J pour se rend dans ce havre de paix montagnard.


 Après avoir été consultée, les équipes Synotis ont opté pour une montée en E-Bike (VTT électrique) vers le Sunnegga. Après une soirée éprouvante, nous poursuivons donc notre séminaire sous le signe de l’effort.
Après avoir été consultée, les équipes Synotis ont opté pour une montée en E-Bike (VTT électrique) vers le Sunnegga. Après une soirée éprouvante, nous poursuivons donc notre séminaire sous le signe de l’effort.









