Nos articles précédents ont mis en lumière la capacité de la gouvernance de données à répondre avec efficacité à certains cas d’usage, ainsi que son rôle pour aider les entreprises à prendre conscience du caractère essentiel du partage de l’information, dans l’économie moderne.
Depuis peu, émerge la notion de « culture Data ». En quoi consiste-t-elle et qu’implique-t-elle concrètement ? Peut-elle répondre à ce besoin de partage de l’information ?
Dans cet article, nous vous apportons des réponses claires, et vous démontrons dans quelle mesure la culture Data interagit de manière optimale avec la gouvernance des données.
Définition
La « culture Data » est un terme récent, rendu populaire par la réussite des GAFA. Dès leur création, ces entreprises ont basé leur business model sur l’exploitation des données, en développant une approche innovante d’appropriation, d’analyse et d’utilisation de volumes de données parfois gigantesques. Avec la prise de conscience de la valeur des données, cette tendance s’est progressivement répandue, pour finalement s’affirmer comme une culture d’entreprise à part entière, au sein de laquelle les données servent non seulement à créer de la connaissance, mais surtout à aiguiller la stratégie de l’entreprise. La « culture Data » était née.
Ni GAFA, ni start-up, et pourtant …
Dans les conférences sur la digitalisation, on se réfère souvent à l’histoire de Kodak, le géant de la fabrication et du traitement des pellicules photo argentiques. N’ayant pas su prendre le virage du numérique, l’entreprise a, en quelques années, quasiment disparu. Mais cet échec relève plus d’un changement profond des habitudes de consommation auquel Kodak n’a pas cru, que d’un problème inhérent à la transformation numérique de ses propres processus. L’exemple démontre à quel point une entreprise peut péricliter rapidement si elle ne fait pas évoluer son modèle économique. Rien de plus naturel.
Toutefois, les entreprises ne sont pas toutes confrontées à une disruption. L’enjeu pour la majorité d’entre elles n’est pas de se réinventer. Il s’agit plus classiquement de s’adapter au mieux et le plus rapidement possible aux nouvelles habitudes et exigences de leurs clients. La réponse réside clairement aujourd’hui dans la digitalisation des services.
Les changements pourraient paraître moins radicaux d’un point de vue stratégique, mais leur impact ne doit pas être négligé. La question consiste à comprendre comment passer d’un fonctionnement en silo, centré sur la satisfaction d’un objectif métier, à une circulation fluide de l’information pour répondre à des besoins multiples ?
Si une partie de la réponse relève de la technique, celle-ci ne résout pas tout. Le risque est de créer de nouveaux silos, avec des nouveaux métiers spécialisés dans le traitement des données, isolés de leurs collègues producteurs de données. Pour une réussite pérenne, l’entreprise doit prendre conscience de l’importance de la destination des données produites et des nouvelles utilisations potentielles, créatrices de connaissances et donc de valeur.
Ainsi, la Culture Data symbolise la prise de conscience généralisée et collective des acteurs de l’entreprise quant à l’importance et la valeur des données. La donnée produite par un service doit être accessible par tous, pour favoriser d’autres utilisations. Il s’agit, en réalité, d’étendre les notions de travail collaboratif à tout ce qui concerne les données. La culture Data rejoint ici de nombreux principes portés par la gouvernance des données.
Partager ses connaissances
D’innombrables projets de digitalisation foisonnent dans les entreprises aujourd’hui. Mais ils sont souvent freinés par des obstacles internes, principalement liés à la résistance au changement et à une faible compréhension des objectifs. Vos collaborateurs ont besoin de connaître les impacts que cette digitalisation aura sur leur rôle, ainsi que les conséquences sur leur travail quotidien.
Au même titre que la gouvernance des données, la culture Data est un ensemble de bonnes pratiques visant à étayer la cohérence des actions menées autour de la donnée. Chaque producteur et chaque utilisateur potentiel de données a besoin de s’approprier un nouveau mode de fonctionnement. En plus de son travail habituel, il doit comprendre où il se situe dans la chaîne de traitement de l’information et dans quelle mesure telle ou telle information peut être exploitée par d’autres services.
En schématisant, voici l’objectif simplifié du développement d’une culture Data :
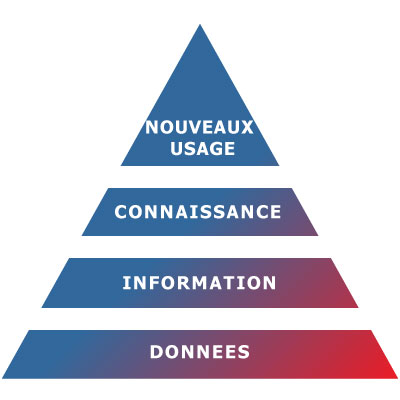
Les données sont à la source de l’information. En impliquant fortement les collaborateurs, les informations sont transformées en connaissances pouvant mener à l’émergence de nouveaux usages.
Les spécialistes de l’IT savent qu’une architecture en silo est une vision de l’entreprise où chaque département agit de manière autonome pour satisfaire ses propres besoins et contraintes. La connaissance s’est calquée sur le même schéma dans les modèles d’entreprise standards jusqu’à former des silos informationnels. Ce sont des niches de savoir associées à un département, un métier, ou un domaine d’activité au sein de votre organisation.
Partager la connaissance représente un atout encore sous-estimé qui implique de changer de paradigme. Cette prise de conscience est impérative pour favoriser l’accessibilité, l’homogénéité et la cohérence des données. Développer une culture Data signifie en finir avec les architectures « silotées » et mettre la donnée au centre des échanges. Fini le travail isolé. Une donnée existe, elle a potentiellement de la valeur pour d’autres, et quand je la produis, au-delà de la réalisation de ma tâche, je me soucis de son utilisabilité pour les autres (qualité, complétude, fraîcheur, etc.). La collaboration et le partage de connaissances participent activement à la création de cette culture.
« La connaissance est la seule ressource, qui une fois partagée, s’en retrouve multipliée » Idriss Aberkane, « L’âge de la connaissance ».
Comment développer sa « culture Data » ?
Développer une culture Data n’est pas naturel pour des entreprises qui reposent sur des modes organisationnels traditionnels, souvent éloignés de ceux des start-ups. Il s’agit donc de la développer progressivement et de façon non invasive, en établissant prioritairement un plan de communication pour faciliter la prise de conscience et la sensibilisation. L’élaboration de plans de formation permettra en outre de partager un langage commun, tout en alertant les collaborateurs sur les conséquences d’un partage d’informations erronées.
L’utilisation de tous les supports de communication disponibles dans l’entreprise facilite bien sûr la circulation de l’information. Parmi eux, l’accès au catalogue des données doit être universel. Chacun doit pouvoir se situer dans la chaîne de traitement d’une information. C’est le meilleur moyen de prendre conscience de son importance et d’échanger avec ses collègues. Des actions de formation à l’utilisation du catalogue devront donc être menées régulièrement. (Dans notre prochain article, nous vous expliquerons dans quelle mesure un catalogue de données aide les organisations à gouverner leurs données et à développer une culture Data).
Les changements d’habitudes réclament du temps. Ils doivent être accompagnés pour s’inscrire dans la durée. Créer des espaces de partage en dehors des silos métiers permet d’optimiser la transversalité. La culture Data prend alors tout son sens et s’ancre dans la durée.
Tout changement peut poser problème à chacun de nous. Changer nous engage à sortir de notre zone de confort, ce que peu de personnes acceptent volontiers. Nous devons être convaincus que l’effort à fournir va nous apporter des bénéfices. Les leviers utilisés doivent donc être pertinents et s’adapter à la culture de l’entreprise. Ainsi, les agents d’une administration ont pour mission d’apporter un service aux citoyens. L’implication dont ils font preuve dans l’accomplissement de cette tâche est souvent admirable, et la seule idée qu’une erreur dans la communication d’information pourrait ternir l’image du service public est un excellent levier d’amélioration des pratiques.
Si elle n’est pas organisée, la mise en place d’une culture Data peut, de surcroît, aboutir à des situations erratiques autour de la donnée, notamment en favorisant des usages non conformes, mais aussi la transmission d’informations à des personnes non autorisées. Un cadre est nécessaire pour s’assurer que cette nouvelle culture Data ne soit pas un moteur de confusion pour l’entreprise.
Pas de culture Data sans gouvernance
La gouvernance de données et le développement d’une culture Data sont deux notions étroitement liées. Aborder le développement d’une stratégie Data et d’une culture associée est un projet dont la réussite est illusoire sans la mise en place de règles formelles. De la même manière, la gouvernance de données ne saurait exister sans le développement de politique du changement et d’éducation des parties prenantes.
Toutes les actions doivent être soutenues par une organisation pérenne. La gouvernance des données joue un rôle prépondérant, puisque c’est elle qui définit et met en œuvre les règles de fonctionnement liées aux données. Elle assure en outre un énorme travail de collecte et d’investigation, mais aussi d’organisation et de définition des responsabilités.
Grâce à la vision globale qu’elle procure, la gouvernance de données permet de réaliser des actions de communication interne selon la maturité de la culture Data et le niveau de déploiement d’actions de gouvernance (outils et mécanismes). La culture Data devient, en retour, un vecteur de communication pour la gouvernance.
Par définition, la gouvernance des données a un rôle d’arbitre et favorise le développement d’une culture autour de la donnée qui sera un vecteur de communication. Il est important de comprendre que l’interdépendance de ces deux disciplines est réelle et qu’il serait aberrant de les aborder séparément.